Card màn hình GPU NVIDIA A100 Tensor Core 80GB HBM2 là một sản phẩm cao cấp được NVIDIA ra mắt trong lĩnh vực tính toán đám mây, trung tâm dữ liệu, AI và HPC. Được hỗ trợ bởi Kiến trúc NVIDIA Ampere, A100 là động cơ của nền tảng trung tâm dữ liệu, tăng tốc cho hàng loạt khối lượng công việc, xử lí chuyên dụng cho hàng loạt các tác vụ kho khăn nhất hiện nay.

A100 cung cấp hiệu suất cao hơn tới 20 lần so với thế hệ trước và có thể được chia thành bảy phiên bản GPU để tự động điều chỉnh theo nhu cầu thay đổi (vGPU). A100 80GB ra mắt băng thông bộ nhớ nhanh nhất thế giới với hơn 2 terabyte mỗi giây (TB/s) để chạy các mô hình và bộ dữ liệu lớn nhất.

Tính năng Tensor Core: NVIDIA A100 Tensor Core 80GB được tích hợp với tính năng Tensor Core, cho phép tăng tốc độ tính toán trong các ứng dụng Deep Learning, tăng độ chính xác và giảm thời gian Deep Learning Training.
The Most Powerful End-to-End AI and HPC Data Center Platform
NVIDIA Tesla A100 80GB là một phần của giải pháp NVIDIA data center hoàn chỉnh, đại diện cho nền tảng HPC và AI đầu cuối mạnh mẽ nhất dành cho trung tâm dữ liệu, nó cho phép các nhà nghiên cứu nhanh chóng cung cấp kết quả trong thế giới thực và triển khai các giải pháp vào sản xuất trên quy mô lớn.
Chúng ta hãy cùng nhau tìm hiểu các khả năng cụ thể của NVIDIA A100 80GB
Deep Learning Training
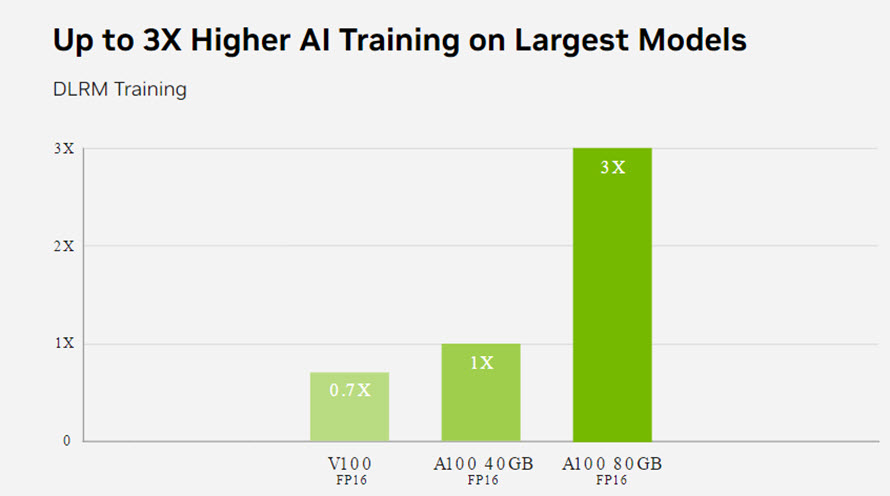
Các mô hình của AI đang ngày càng trở lên phức tạp, bắt đầu chỉ với các công việc đơn dản như phân loại và xử lí phần đầu của công việc, giờ đây, chúng có thể tự đưa ra ý kiến, lập trường, và hoàn toàn có thể tự động làm chủ của một hệ thống lớn. Nhưng điều thiết yếu nhất để làm được việc đó chúng ta cần phải cho AI môi trường học tập đủ lớn, hay còn được biết đến với cái tên Deep Learning Training
NVIDIA A100 Tensor Cores với công nghệ Tensor Float (TF32) cung cấp hiệu suất cao hơn tới 20 lần so với NVIDIA Volta mà không cần thay đổi mã và tăng thêm 2 lần với độ chính xác hỗn hợp tự động và FP16. Khi được kết hợp với NVIDIA® NVLink®, NVIDIA NVSwitch™, PCI Gen4, NVIDIA® InfiniBand® và SDK NVIDIA Magnum IO™, bạn có thể mở rộng tới hàng nghìn GPU A100, cung cấp môi trường khổng lồ cho việc suy luận sâu.
Một ví dụ như: Khối lượng công việc đào tạo như BERT có thể được giải quyết trên quy mô lớn trong vòng chưa đầy một phút bằng 2.048 GPU A100, một kỷ lục thế giới về thời gian giải quyết.
Khả năng phân vùng GPU (vGPU)
GPU A100 bao gồm khả năng phân vùng GPU và ảo hóa GPU đa phiên bản (MIG) mới , đặc biệt có lợi cho các nhà cung cấp dịch vụ đám mây (CSP). Khi được định cấu hình để vận hành MIG, A100 cho phép CSP cải thiện tốc độ sử dụng của máy chủ GPU của họ, mang lại số phiên bản GPU nhiều hơn gấp 7 lần mà không phải trả thêm phí.

Mỗi GPU trong giải pháp MIG được tách ra từ 1 GPU vật lý hoạt động hoàn toàn riêng biệt, nên có thể chạy các tác vụ hoàn toàn khác nhau. Khả năng cách ly lỗi mạnh mẽ cho phép họ phân vùng một GPU A100 một cách an toàn và bảo mật.
Công nghệ TensorFloat-32 (TF32) Tensor Core mới trong A100 cung cấp một đường dẫn dễ dàng để tăng tốc dữ liệu đầu vào/đầu ra của FP32 trong DL và HPC, chạy nhanh hơn 10 lần so với các hoạt động của V100 FP32 FMA hoặc nhanh hơn 20 lần với sparsity. Đối với DL có độ chính xác hỗn hợp FP16/FP32, Lõi A100 mang lại hiệu suất gấp 2,5 lần so với V100.
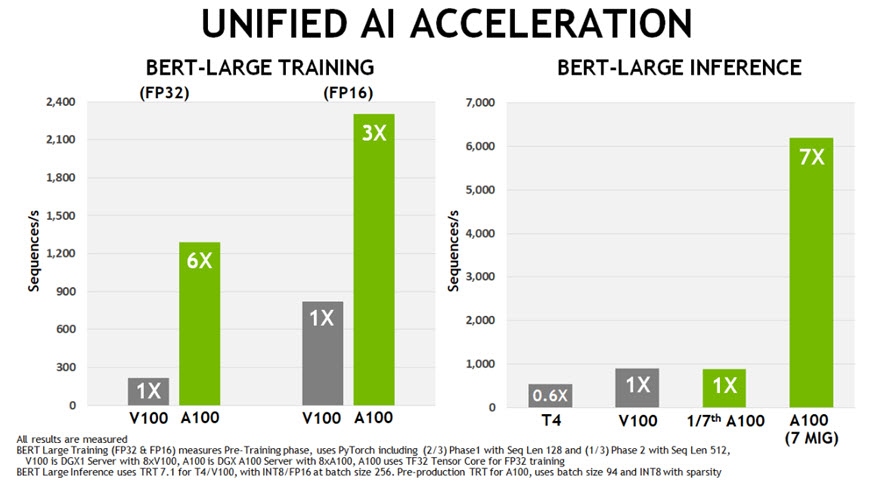
Third-generation NVIDIA NVLink
Kết nối NVLink tốc độ cao thế hệ thứ ba của NVIDIA được triển khai trong GPU A100 và NVIDIA NVSwitch mới giúp tăng cường đáng kể khả năng mở rộng, hiệu suất và độ tin cậy của nhiều GPU. Với nhiều liên kết hơn trên mỗi GPU và bộ chuyển mạch, NVLink mới cung cấp băng thông giao tiếp GPU-GPU cao hơn nhiều, đồng thời cải thiện các tính năng phát hiện và khôi phục lỗi.
NVLink thế hệ thứ ba có tốc độ dữ liệu 50 Gbit/giây trên mỗi cặp tín hiệu, gần gấp đôi tốc độ 25,78 Gbit/giây trong V100. Một A100 NVLink duy nhất cung cấp băng thông 25 GB/giây theo mỗi hướng tương tự như V100, nhưng chỉ sử dụng một nửa số cặp tín hiệu trên mỗi liên kết so với V100. Tổng số liên kết được tăng lên 12 trong A100, so với 6 trong V100, mang lại tổng băng thông 600 GB/giây so với 300 GB/giây đối với V100.
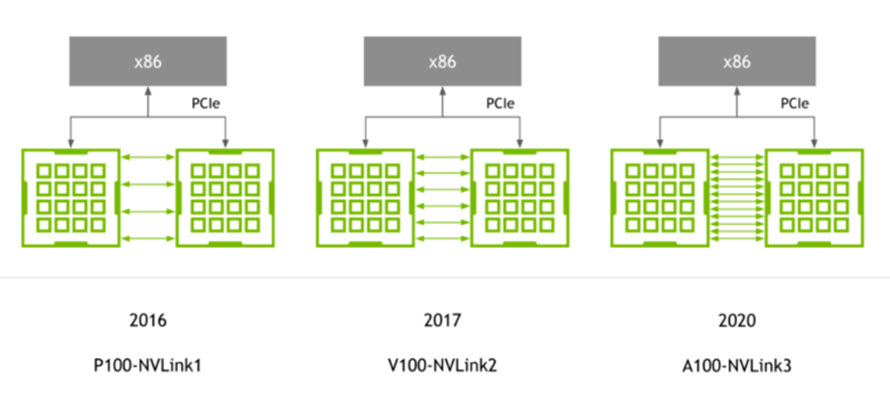
PCIe thế hệ thứ 4 với SR-IOV
GPU A100 hỗ trợ PCI Express Gen 4 (PCIe Gen 4), giúp tăng gấp đôi băng thông của PCIe 3.0/3.1 bằng cách cung cấp tốc độ 31,5 GB/giây so với 15,75 GB/giây đối với kết nối x16. Tốc độ nhanh hơn đặc biệt có lợi cho GPU A100 kết nối với CPU hỗ trợ PCIe 4.0 và để hỗ trợ các giao diện mạng nhanh, chẳng hạn như InfiniBand 200 Gbit/giây.
A100 cũng hỗ trợ ảo hóa đầu vào/đầu ra gốc đơn (SR-IOV), cho phép chia sẻ và ảo hóa một kết nối PCIe duy nhất cho nhiều quy trình hoặc máy ảo.
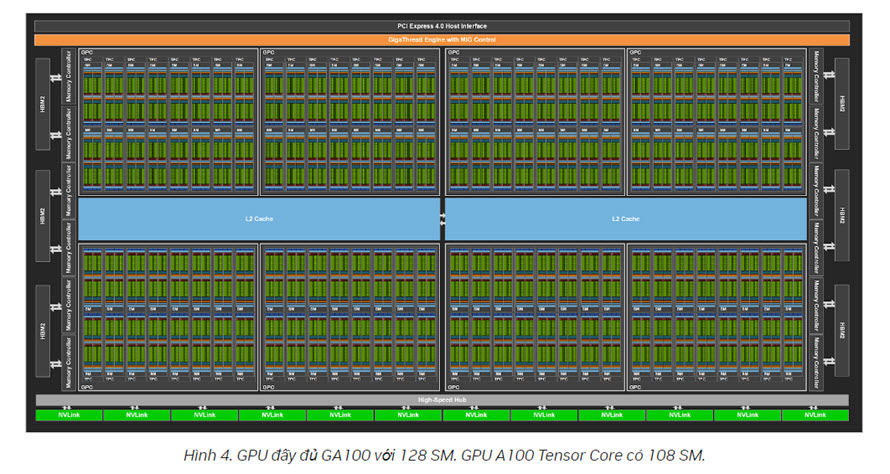
Kiến trúc phần cứng GPU A100
GPU NVIDIA GA100 bao gồm nhiều cụm xử lý GPU (GPC), cụm xử lý kết cấu (TPC), bộ đa xử lý phát trực tuyến (SM) và bộ điều khiển bộ nhớ HBM2.
A100 Tensor Core tăng tốc HPC
Nhu cầu về hiệu suất của các ứng dụng HPC đang tăng lên nhanh chóng. Nhiều ứng dụng từ nhiều lĩnh vực khoa học và nghiên cứu dựa trên tính toán độ chính xác kép (FP64).
Để đáp ứng nhu cầu tính toán ngày càng tăng nhanh của điện toán HPC, GPU A100 hỗ trợ các hoạt động Tensor giúp tăng tốc tính toán FP64 tuân thủ IEEE, mang lại hiệu suất FP64 gấp 2,5 lần so với GPU NVIDIA Tesla V100.
Mỗi SM trong A100 tính toán tổng cộng 64 thao tác FP64 FMA/đồng hồ (hoặc 128 thao tác FP64/đồng hồ), gấp đôi thông lượng của Tesla V100. GPU A100 Tensor Core với 108 SM mang lại thông lượng FP64 cao nhất là 19,5 TFLOPS, gấp 2,5 lần so với Tesla V100.
Với sự hỗ trợ cho các định dạng mới này, Lõi căng A100 có thể được sử dụng để tăng tốc khối lượng công việc HPC, bộ giải vòng lặp và nhiều thuật toán AI mới.

GPU NVIDIA Tesla A100 80GB HBM2e còn rất nhiều ứng dụng và khả năng khác nữa mà trong một bài viết không thể nào liệt kê hết được, nhưng trên đây là những điểm cần quan tâm nhất của người sử dụng GPU hiện nay.
Nhìn chung, với giá thành khá lớn của mình NVIDIA Tesla A100 80GB HBM2e hoàn toàn đáp ứng được mọi nhu cầu của người sử dụng cần.
Biên soạn nội dung: Team Marketing MCN
==========================
Công Ty Cổ Phần Máy Chủ Nhanh
ĐT: 024.8585.7899; Hotline: 0888.002.000
MÁY CHỦ - SERVER - MÁY TRẠM - WORKSTATION - LINH KIỆN MÁY CHỦ - GIẢI PHÁP MÁY CHỦ - NETWORK
SOFTWARE - THIẾT BỊ LƯU TRỮ NAS - LAPTOP - PC - DESKTOP - WINDOWNS SERVER - SQL SERVER - OFFICE


.png)





![[Review] Hình ảnh Máy Chủ (Server) Dell PowerEdge EMC R740 Rack (2U)](https://maychunhanh.vn/upload/img/review-may-chu-dell-poweredge-r740.jpg)

![[Review] máy chủ (Server) Lenovo Thinksystem SR550 Rack (2U)](https://maychunhanh.vn/upload/img/review-may-chu-lenovo-thinksystem-sr550.JPG)
![[Review] máy chủ (Server) Dell PowerEdge EMC T440 Tower (5U) tại Máy Chủ Nhanh](https://maychunhanh.vn/upload/img/dell-poweredge-t440-s4210.jpg)

![[Review] đánh giá máy chủ (Server) HPe ProLiant DL380 Gen10](https://maychunhanh.vn/upload/img/server-hpe-dl380-gen10.jpg)
![[Review] và đánh giá máy chủ Dell PowerEdge R640 Rackmout 1U](https://maychunhanh.vn/upload/img/dell-emc-R640-server.jpg)
![[Máy Chủ Nhanh] đánh giá máy chủ Dell PowerEdge R440 Rackmout 1U](https://maychunhanh.vn/upload/img/dell_poweredge_r440_review.jpg)
![[Máy Chủ Nhanh] chi tiết về máy chủ Lenovo Thinksystem ST550 Tower Rackmout 4U](https://maychunhanh.vn/upload/img/lenovo-thinksystem-st550-silver-4110.jpg)
![[Review] Hình ảnh thực tế máy chủ (Server) Dell PowerEdge EMC R740XD](https://maychunhanh.vn/upload/img/dell-poweredge-r740xd-review-may-chu.jpg)
![[Review] thiết bị lưu trữ Synology RS819 NAS 4 Bay Storage (HDD/SSD)](https://maychunhanh.vn/upload/img/storage-synology-rs819-6-bay.jpg)
![[maychunhanh.vn] Đánh giá chi tiết máy chủ Dell PowerEdge R750](https://maychunhanh.vn/upload/img/review-may-chu-dell-poweredge-r750.jpg)
![[maychunhanh.vn] Đánh giá chi tiết máy trạm Dell Precision 3650 Tower](https://maychunhanh.vn/upload/img/review-may-tram-dell-precision-3650-tower-cto-base.jpg)
![[maychunhanh.vn] Đánh giá chi tiết máy chủ Dell PowerEdge R650 Server](https://maychunhanh.vn/upload/img/dell-poweredge-r650-review.jpg)















